2026.03.05
GitHub Copilotでバイブコーディングを試してみた!
#AI #GitHub Copilot #バイブコーディング #ETロボコン #電気電子 #組込制御
トップ > 技術ナレッジのアーカイブ > GitHub Copilotでバイブコーディングを試してみた!
2026.03.05
#AI #GitHub Copilot #バイブコーディング #ETロボコン #電気電子 #組込制御

この記事では、GitHub Copilotを使用してバイブコーディングでPID制御シミュレータを作成します。
PID制御シミュレータを作成したときに参照したことや考えたこと、プロンプト例を示します。
生成されたコードについてもレビューをしていますので、1からAIにコードを生成してもらった時の参考にしてください!
2024年にテクノプロ・デザイン社に新卒入社。 主に組込みシステム開発を担当しています。ネットワークが好きでパケットキャプチャするのが好き。ゲーミングデバイスも好きで、愛用ガジェットは、VAXEE XE Wireless(4K)とVAXEE PA B22。
バイブコーディングとは、簡単に言えば、AIを使って気の向くままにアプリケーションを作成するスタイルを指します。
提唱者は、アンドレイ・カーパシー(Andrej Karpathy)氏です。2025年から広く使われ始めたので最近使われ始めた言葉です。
日本では「AI駆動開発」「AIペアプログラミング」など、既存の語に“AI”を付した用語が一般的です(明確な定義はまだ定まっていません)。 言葉の語源は、人がバイブスをもとにソフトウェアをAIに作ってもらうコーディングをしようとのことです。
具体的には、結合テスト用のツールを作成するときや簡単なスクリプトを作ってもらうなどです。
人はコーディングに集中するより、作成したいソフトウェアの機能や使いやすさなど「実装をするには面倒だけどもAIに指示を出すと思った以上に簡単に実装できるのは?」と思う機能にどんどん使っていくとよいと私は思います。
また、そもそもツールの使いやすさもAIと対話をしながら作成していくのも一つの手です。AIはUIのブラッシュアップをするときに有用な場合があります。
私もCUIアプリケーションをGUIアプリケーションにしたいときはバイブコーディングを活用します。(UIについて詳しく指示をしていなくても使いやすいアプリになります。)
一方で欠点もあります。バグの発生、セキュリティの甘さ、可読性の低下、変更への脆弱さなど、さまざまなリスクが想定されます。
これらを加味してバイブコーディングをする場合と、従来のコーディングスタイルをとるのか、を選択することが重要になります。
<まとめ>
バイブコーディングの紹介は以上となります。
今回はVSCode + GitHub Copilotを利用してバイブコーディングを試します。下記URLからダウンロードします。
VSCodeのダウンロード(Visual Studio Code Homepage)
GitHub Copilotの設定についてはこちら(VSCode GitHub Copilot Setup Page)
今回は、PID制御シミュレータを作成してもらいます。
この章では、シミュレータに必要な機能とプロンプトの作成について解説します。
まず、PID制御について簡潔に説明します。
PID制御は、ロボット制御で利用されるフィードバック制御の手法です。このPID制御器には、3つの定数を決める必要があります。
それぞれの関係については、話し出すと1つの記事を書くことが可能になりますので省略します。ご興味がある方は出典の「PID制御」のURLから著名なページをご覧ください。(記事最下部)
シミュレータを作成するときに考慮しないといけないのは、目標値、P・I・Dの4パラメータです。ご存じの方に、思い出すということで重要な式のみ掲載します。
- u(t) = K_p e(t) + K_i ¥int_{0}^{t} e(¥tau) ¥, d¥tau + K_d ¥frac{d e(t)}{d t}
この式は LaTeX/Markdown 特有の表記のため、正式な数式表記への差し替えが必要です。
PID制御の説明はここまでです。
これからはバイブコーディングの前準備として必要な機能・言語とLLM(Large Language Models:大規模言語モデル)を選択します。
今回は、執筆当時(2025/12)に話題に上がったGemini 3 Proモデルを使用してみたいと思います。
言語と使用するサービスは以下です。
生成時は有料版GitHub Copilotを使用します。無料版では様々な制限があり、思い通りにいかない場合もあります。
作りたいものと環境が決まったので、機能について考えてみましょう。
何もないところから作成するのは難しいので、既存のシミュレータを参考にして機能を洗い出してみましょう。
シミュレータは、入力があって演算をして出力が何かを見るので、このような機能があるといいかもしれません。
- 入力値の乱数生成アルゴリズムを選択できる
- 入力値を指定することができる
- 入力値をエクスポートすることができる
- 入力値と出力値を合わせてグラフ表示してくれる
- 出力値を見ることができる
- 定数を変更しやすくする(P,I,Dの編集をUI上できる)
上記の機能を作成してもらうとシミュレーションしやすいと思いますので、これをプロンプトに書き記しましょう。(これ以外にも欲しい機能はたくさんあると思いますが、初めは小さく実装してもらうことが重要です。初めから多くの機能が欲しいと伝えても実装されない場合やバグの原因となることがあります)
あなたは、Pythonでシミュレータを作成することを熟知しているエンジニアです。
PID制御のシミュレータを作成してください。
本書にはシミュレータに実装してもらいたい機能について記載されています。
この機能は必ず実装してください。実装漏れしていると使用者にクリティカルな影響を与えます。
まず、本書を十分に読みTODOリストを作成してから実装に入ってください。
実装するときはステップバイステップで実行してください。
シミュレータ画面上でPID値,目標値を簡単に変更できること その際に入力値は、小数第3位まで対応すること。それ以下は禁止。
3種類以上のノイズを利用できること。
ただし、PID制御のシミュレーションに使用されている標準的なノイズにして下さい。
例:ステップランダム、Mシーケンス
入力値や出力値を表示するグラフを作成できること。
これは必要機能4つ目にある入力値・出力値・目標値をインポートされたときにも、即座にグラフを表示すること。
入力値・出力値・目標値のインポート・エクスポートができること。
csv形式で保存すること、ヘッダーを必ずつけてください(目標値、入力値、出力値)としてください
この章では、生成したシミュレータを実際に動作させてみて必要な機能実装が意図通り実装されているかを動作確認をしてみましょう。
確認項目は以下です。
- 文字化けしていない
- 出力、目標値、入力値を含むグラフが出ている
- P,I,D入力が小数点第3位までできる
- 数値入力箇所に文字入力できない
- 言語が混在していない
- ボタンが正常に動作している
- 設定関連は一か所にまとまっている
- ノイズ生成器が正しく動作している
- 3つ以上のノイズ生成器を使用可
- PID演算を間違っていない
- ヘッダー付きのcsvを出力できること
- インポートできること

起動時画面はシンプルで分かりやすいですね。ウィンドウ名に「PID Simulator」とあり、設定類もきちんとグルーピングされているので非常にわかりやすいです。
言語は英語です。英語ですべて統一されているかは見ていきましょう。
また、グラフが出ていないのでグラフ名が出てないです。よってシミュレーションしたときに出るものと考えられるので実行したときに文字化けしないかを見ないといけませんね。
ノイズは3つ以上使用可であってほしいです。確認しましょう。
図2を見るとノイズ生成器は、「ホワイトノイズ、Mシーケンス、ランダムステップ」の3つが選択できますね。
ホワイトノイズから順番にシミュレーションを実行していきましょう。
ホワイトノイズを実行してみましょう。
初期値がそれぞれの設定に入っているので「Run Simulation」を押して実際に動作させてみましょう。
(目標値:10 P:1.0 I:0.1 D:0.01 時間:50s ノイズ:ホワイトノイズ)
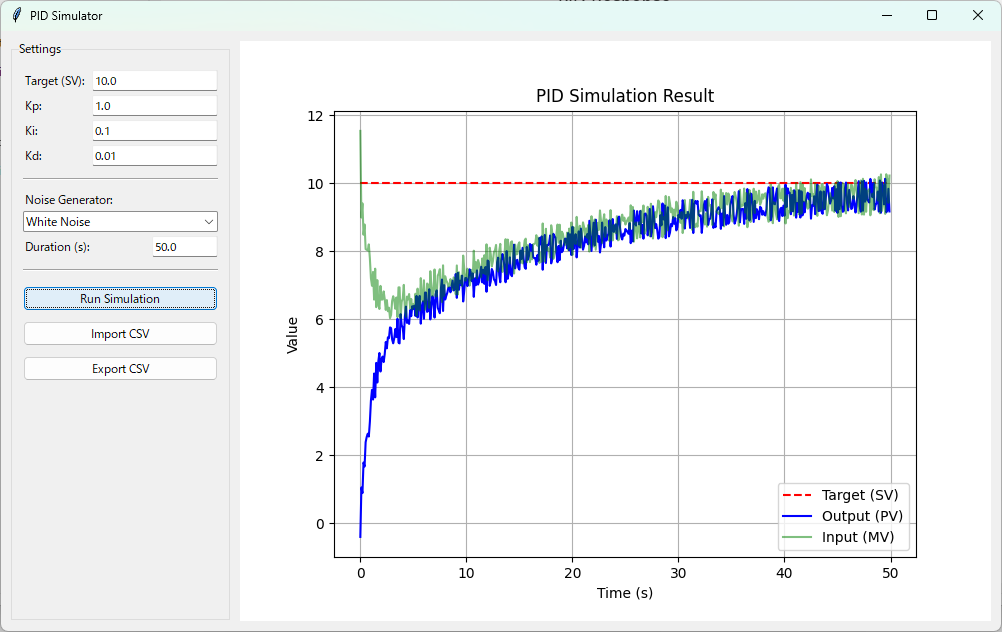
図3全体を見ると目標値(オレンジ線)、入力値(黄緑色)、出力値(青色)、表題「PID Simulation Result」とラベルが問題なく出力されていますね。見た目上は大丈夫そうです。
ぱっと見は妥当そうです。次に、実際のデータを確認します。
「Export CSV」を押してcsvを出力しましょう。
問題なくcsvを出力できましたね、CSVデータを見てみましょう。
目標値,入力値,出力値
10.0,11.542462148956686,-0.398614548609626
10.0,8.994451328796858,1.0537597854308787
10.0,9.410686311632276,0.8902146076960356
10.0,8.488299555620177,1.7885300060398666
10.0,8.789792869020017,1.671820930701259
10.0,8.066504909096146,2.387946014559816
10.0,8.046622613067969,2.538950829216063
10.0,8.027455953092506,2.637038787007888
10.0,8.205021465072782,2.552239594150976
10.0,7.791051144994309,2.984643202125095
・・・
ヘッダーは「目標値,入力値,出力値」と指定していました。データ1のヘッダーを見ると指定通りになっているのでOKですね。
データ1からデータが小数点第15位まで出力されています。これらから演算でも小数点第15位まで利用されていそうです。
小数点以下をどこまで使っているのかはコードレビューする中でも重要なので確認していきましょう。
次は、Mシーケンスを見てみましょう。
(目標値:10 P:1.0 I:0.1 D:0.01 時間:50s ノイズ:Mシーケンス)
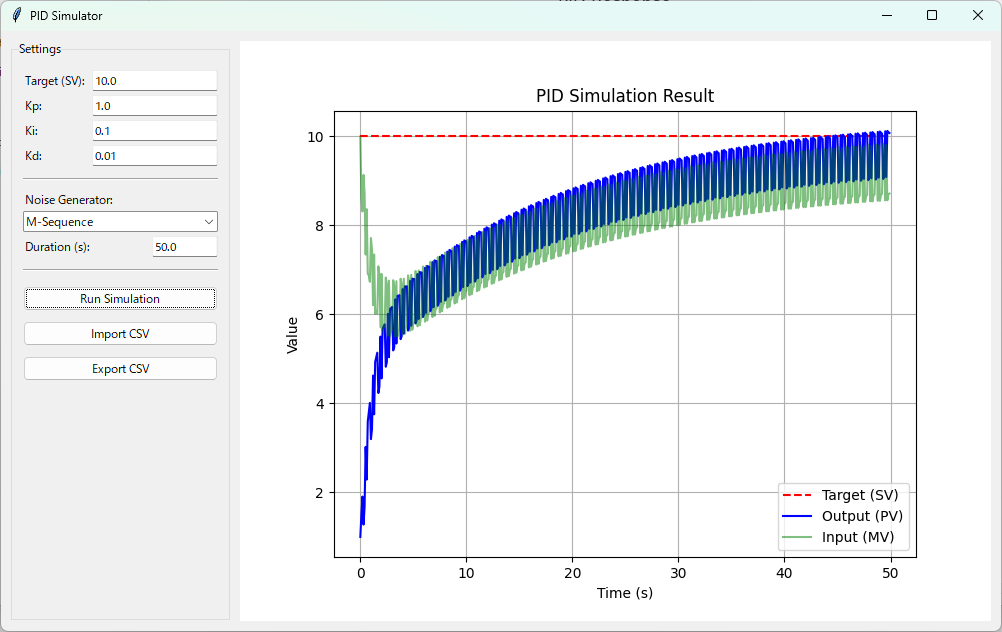
Mシーケンスのノイズが入っていそうですね。 これもデータをcsvで出力してみましょう。
目標値,入力値,出力値
10.0,8.625555000000002,1.4995
10.0,8.309513947500001,1.9058027500000003
10.0,9.13018022353875,1.2759883098750002
10.0,8.718531245219161,1.6686979055581876
10.0,7.339849475380714,3.0211895725412363
10.0,8.359701121746015,2.2871225676832103
10.0,6.916395085832896,3.5907514953863506
10.0,6.870777244379562,3.807033674908678
10.0,6.728797357477075,4.010220853382222
・・・
最後にランダムステップを見ていきましょう。
(目標値:10 P:1.0 I:0.1 D:0.01 時間:50s ノイズ:ランダムステップ)
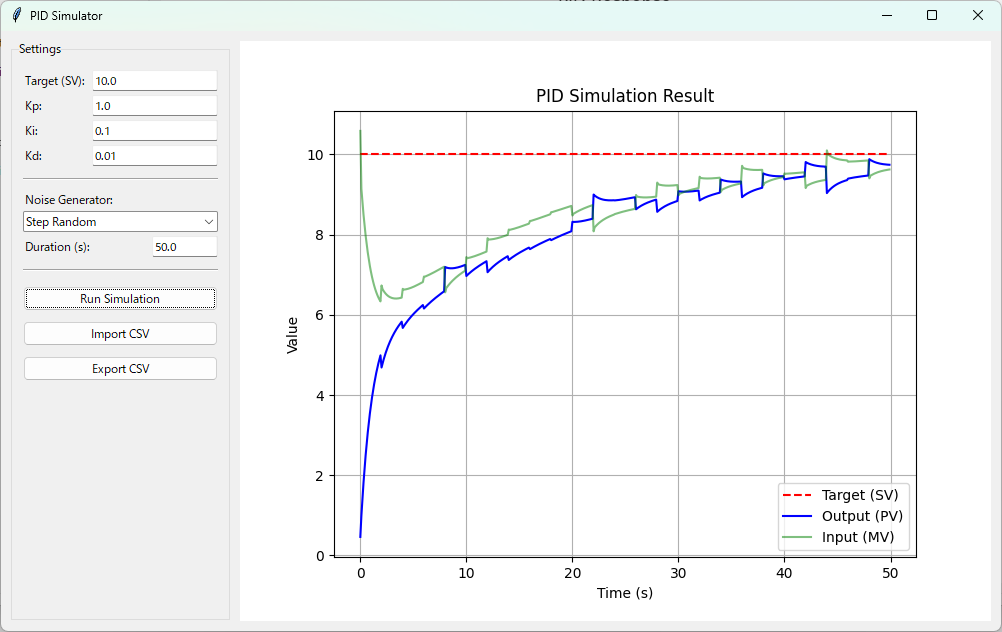
入力値のPが大きいので投入が大きくなってますね。また、出力が経過時間内に目標の10に到達していないので入力値も10まで到達していないです。
これもcsv出力してみてみましょう。
目標値,入力値,出力値
10.0,10.5881047375963,0.46116690306639574
10.0,9.141969945935681,0.9905721399462107
10.0,8.807007406871602,1.4212003753990041
10.0,8.500351173295975,1.8135490721259537
10.0,8.22473827251229,2.1709475223377748
10.0,7.977188492555223,2.4966954049998202
10.0,7.755034197291921,2.79377840453091
10.0,7.555860253581299,3.0648995393222807
10.0,7.377480288905653,3.3125059201885514
10.0,7.21791502720641,3.5388129837777265
・・・
データを見てみるとノイズが一定周期で入っているのか確認することができません。
これは出力値の演算を見て見てみないとわからない上に、ノイズに関する項目を追加してもらわないといけないです。
次の章で実装をチェックします。
そこでも触れますが出力値を演算するときにノイズを乗せていない出力値を求めてそこにノイズをプラスする実装になっています。
このノイズを乗せていない出力値も乱数なのでノイズの動作を確認するならばノイズをcsvに出してもらうのがよいかと思います。
それではシミュレータ上の入力ができる箇所の動作確認をしてみましょう。
確認するのは「Settings」のボタンやコンボボックス、ラベルです。ボタン操作(シミュレーション実行/CSV 出力)は既に確認済みのため、本節では対象外とします。コンボボックスも同様に省略します。
ラベルについては、PIDのパラメータ選択やテスト時間があります。数字を入力することを想定しているので文字を入力したときや何も入力していないときの挙動を見てましょう。
見るのは以下の項目を確認します。
P.I.DのPパラメーターに文字を入力してみましょう。
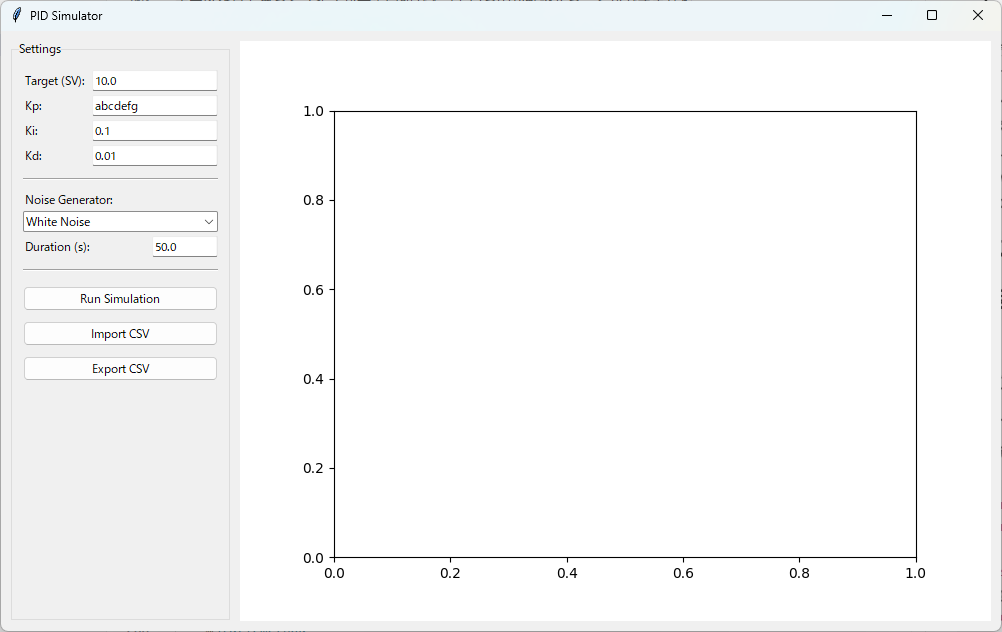
シミュレータ画面上では文字列を入力できエラーメッセージも出ていきませんでした。
この状態からシミュレーションしてみましょう。
実行すると下のエラーメッセージが表示されました。
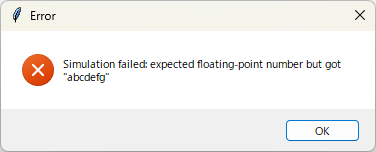
シミュレーションできないことと小数点を含む数値を入力してほしいとエラーが出ています。
入力なしの動作を見てみましょう。
シミュレータ画面上では何も入力していない状態になり、エラーメッセージもでてきませんでした。
シミュレーションしてみましょう。
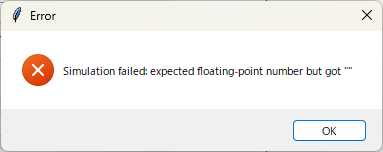
入力なしでも文字入力と同じエラーメッセージが出力されていますね。
では、実装を見てみましょう。
実装確認するときに今回見ていく処理の優先順位をつけていきます。
高:演算処理
中:出力・入力
低:UI
記事に記載するのは高優先度のみです。中・低優先度の項目は動作確認で確認できているので実装は見なくてもいいかなと思います。
tipsになりますがPythonでバイブコーディングしている場合はtinkerをよく利用しています。
演算処理を見ていく前に処理の流れを簡単にソースコードを見て確認しましょう。
- import tkinter as tk
- from tkinter import ttk, messagebox, filedialog
- import matplotlib.pyplot as plt
- from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
- import csv
- import numpy as np
- from pid_logic import PIDController, SignalGenerator
- def run_simulation(self):
- try:
- # Parameters (Requirement: Round to 3 decimal places)
- kp = round(self.kp_var.get(), 3)
- ki = round(self.ki_var.get(), 3)
- kd = round(self.kd_var.get(), 3)
- target = round(self.sv_var.get(), 3)
- duration = self.duration_var.get()
- noise_type = self.noise_type_var.get()
- # Setup
- dt = 0.1
- steps = int(duration / dt)
- self.pid.set_parameters(kp, ki, kd, target)
- self.pid.reset()
- """
- Generate Noise/Disturbance if strictly needed,
but usually noise is added to the system output or sensor?
Or is it the input signal? The requirement says "Random Generator Types".
Let's assume the noise is added to the Process Value (sensor noise)
OR as an external disturbance. Let's add it as sensor noise for visual impact.- ( 厳密に必要な場合はノイズ/外乱を生成しますが、通常、ノイズはシステム出力またはセンサーに追加されますか?
それとも入力信号ですか?要件には「ランダムジェネレータータイプ」と記載されています。
ノイズがプロセス値(センサーノイズ)に追加されると仮定しましょう。
または、外部外乱として追加されます。視覚的なインパクトを与えるために、センサーノイズとして追加してみましょう。)- if noise_type == "White Noise":
- noise = SignalGenerator.generate_white_noise(steps, -0.5, 0.5)
- elif noise_type == "Step Random":
- noise = SignalGenerator.generate_step_random(steps, interval=20, min_val=-0.5, max_val=0.5)
- elif noise_type == "M-Sequence":
- noise = SignalGenerator.generate_m_sequence(steps) * 1.0 # Scale 0/1 to amplitude
- else:
- noise = np.zeros(steps)
- # Simulation Loop (Simple First Order System Model)
- # System: Tau * dy/dt + y = K * u
- tau = 2.0
- system_k = 1.0
- current_pv = 0.0
- self.time_data = []
- self.target_data = []
- self.input_data = []
- self.output_data = []
- for i in range(steps):
- t = i * dt
- # PID Calculation
- # PV needs noise?
- # Let's add noise to the PV fed to PID (Sensor Noise)
- sensor_pv = current_pv + noise[i]
- mv = self.pid.update(sensor_pv, dt)
- # mv is already rounded in PIDController.update
- # System Update (Euler method)
- # dy/dt = (K*u - y) / Tau
- derivative_pv = (system_k * mv - current_pv) / tau
- current_pv += derivative_pv * dt
- # Store data
- self.time_data.append(t)
- self.target_data.append(target)
- self.input_data.append(mv)
- self.output_data.append(sensor_pv) # Plot noisy sensor data or clean system state? Usually PV implies what user sees.
- self.update_plot()
- except Exception as e:
- messagebox.showerror("Error", f"Simulation failed: {e}")
続いて上記コード1のフローチャートです。
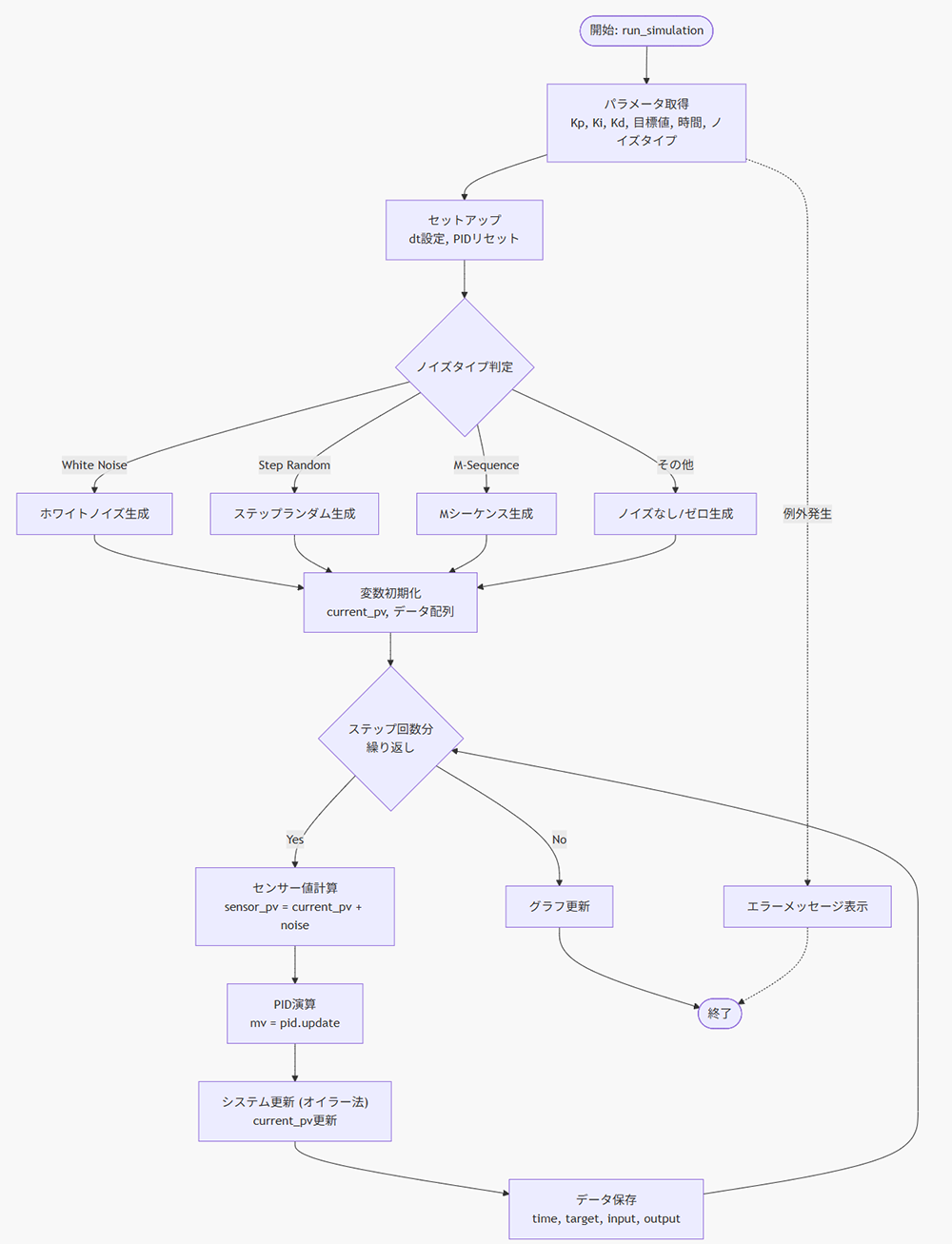
コード1のフローチャートから演算確認するのは大きく分けて4つです。
1で見るのは乱数生成アルゴリズムが正しいかを見ます。
2では、センサー値計算がノイズありの値を使うのかノイズなしの値を使うのかを確認します。
3では、PID式と同じ計算式になるかを確認します。また小数点がかかわってくるので丸め込みされている場合はそれが妥当な丸め込みかを確認します。
4では、システム更新の値がそのあと再更新されるタイミングや表示するのが正しいかを確認します。
初めにノイズ生成処理の演算を見ていきましょう。 ノイズ生成処理は利用できるのは3つですが処理上は4つありますので一つずつ確認していきます。
まず、ホワイトノイズを見ていきます。
- import numpy as np
- import random
- class SignalGenerator:
- @staticmethod
- def generate_white_noise(length, min_val=-1.0, max_val=1.0):
- """白色雑音 (一様乱数)"""
- return np.random.uniform(min_val, max_val, length)
ホワイトノイズは、一様乱数を使ってますね。
ホワイトノイズを生成するときに一様乱数を用いるのは稀だと思います。 私の知っているのは正規分布を使うほうが標準的かと思うので修正してもらいましょう。
次にステップランダムを見ていきましょう。
- import numpy as np
- import random
- class SignalGenerator:
- @staticmethod
- def generate_step_random(length, interval=10, min_val=-1.0, max_val=1.0):
- """ステップランダム信号"""
- signal = []
- current_val = random.uniform(min_val, max_val)
- for i in range(length):
- if i % interval == 0:
- current_val = random.uniform(min_val, max_val)
- signal.append(current_val)
- return np.array(signal)
ステップランダムの実装は問題なさそうですね。
ステップランダムも一様乱数を使っているので正規分布を使った方がいいかもですね。
次にMシーケンスを見ていきましょう。
- import numpy as np
- import random
- class SignalGenerator:
- @staticmethod
- def generate_m_sequence(length, feedback_taps=[2, 3], seed=[1, 1, 1]):
- """M系列信号 (Maximum Length Sequence)"""
- # 単純なLFSR実装
- # feedback_taps: フィードバックを行うビット位置 (1-based index)
- # seed: 初期状態 (全て0は不可)
- state = list(seed)
- signal = []
- n_bits = len(state)
- for _ in range(length):
- # 最後のビットが出力 (0 or 1) -> (-1 or 1 に変換して出力とする)
- output_bit = state[-1]
- signal.append(1.0 if output_bit == 1 else 0.0) # 0/1 のステップとして出力
- # フィードバック計算
- feedback = 0
- for tap in feedback_taps:
- if tap <= n_bits:
- feedback ^= state[tap-1]
- # シフト
- state.pop()
- state.insert(0, feedback)
- return np.array(signal)
最後にノイズなしです。
- import numpy as np
- noise = np.zeros(steps)
numpyのzero埋めをしていますね。
この処理も問題はないのでこのままでよいとします。
シミュレーション実行処理内のノイズ選択処理を見てみましょう。
- if noise_type == "White Noise":
- noise = SignalGenerator.generate_white_noise(steps, -0.5, 0.5)
- elif noise_type == "Step Random":
- noise = SignalGenerator.generate_step_random(steps, interval=20, min_val=-0.5, max_val=0.5)
- elif noise_type == "M-Sequence":
- noise = SignalGenerator.generate_m_sequence(steps) * 1.0 # Scale 0/1 to amplitude
- else:
- noise = np.zeros(steps)
if文を使用してnoise_typeの文字列を判定していますね。
動作上特に問題はありませんが個人的にはmatch文を使った方がきれいかなと思います。
マジックナンバーが多いのも少し気になります。プロンプト内で明記しているものではないので妥当な挙動だと思います。
こういったところは人の手が入る、または機能でカバーできるところはカバーする、になるのかと思います。
以上でノイズ生成アルゴリズムの確認は完了しました。
総評として乱数生成アルゴリズムの選択がマイナーでしたので修正が必要です。
また、UI上で使用できないノイズなしが実装されていました、特に大きな影響はありませんが可読性を犠牲にしているのと、ノイズなしはデフォルトの立ち位置なので実行不可にしてしまってもいいのでは?と思います。
センサー値演算は必ずノイズから始まるようになってます。これは機能改善になると思います。
センサーの初回値が0でノイズによって左右されることは現実問題ほとんどないと考えられます。
例えばカラーセンサーのRGB値を活用する場合、PID制御処理の開始時点でRGB値が0つまり真っ黒のことですが、現実問題真っ黒なことなんて稀です。黒でもRGBのいずれかの値が0以外のことがほとんどだと思うので、0+ノイズ始まりはあまりよくないかなと思います。ユーザが入力するもしくは乱数から決定するどちらかになると思います。
また、センサー値がノイズ込みで累積していっているのも問題かなと思います。これもシミュレーションの利用意図によりますが、センサー値が時間とともに上昇していくよりもそこまで変化のない状態が続くほうが多いと思います。なのでこれはアルゴリズムの変更をしてあげたほうが良いと思います。
一番重要なところです。この演算処理を見てみましょう。
- def update(self, current_value, dt=0.1):
- error = self.target - current_value
- self.integral = self.integral + (error * dt)
- derivative = (error - self.prev_error) / dt
- output = (self.kp * error) + (self.ki * self.integral) + (self.kd * derivative)
- self.prev_error = error
- return output
評価をする前に操作量を求める式を記載します。
この式通りに実装されているかを確認します。
- output = (self.kp * error) + (self.ki * self.integral) + (self.kd * derivative)
が式です。変数名的には正常に実装されています。
errorを確認すると
- error = self.target - current_value
とあります。e(t)は偏差なのでこれは正しいです。
次に、integralです。これは積分文です。時間積分の偏差を求める必要があります。
- self.integral = self.integral + (error * dt)
この処理が該当します。引数でdtをもらうのでdtをいくつで設定しているかを確認します。
コード1からdtは0.1で定義されています。
操作値を求めるときはステップ数に左右されているのでstep = duration / dtなので0.1単位で分割していることがわかります。
これを引数に渡しているのでスケールも問題ないですなので、積分演算も正しいです。
最後に微分定数です。
derivativeが導関数のです。
処理を見てみましょう。
- derivative = (error - self.prev_error) / dt
処理も正しいです。現在の偏差と直前の偏差を経過時間で割っているので正しいです。
以上のことから時間の引数に渡す時間のスケールを間違えなければ正しいPID制御ができます。
実装単位を見ると私は引数dtにデフォルト値を入れるのはちょっと攻めすぎの実装かなと思います。
PIDは時間が重要になります。時間のスケーリングを間違えるだけで大きな誤差になりかねないのでここはデフォルト値の設定はしないほうがいいのではないかなと思います。
- def update(self, current_value, dt):
- error = self.target - current_value
- self.integral = self.integral + (error * dt)
- derivative = (error - self.prev_error) / dt
- output = (self.kp * error) + (self.ki * self.integral) + (self.kd * derivative)
- self.prev_error = error
- return output
最後に更新タイミングと格納データを見ます。
- for i in range(steps):
- t = i * dt
- # PID Calculation
- # PV needs noise?
- # Let's add noise to the PV fed to PID (Sensor Noise)
- sensor_pv = current_pv + noise[i]
- mv = self.pid.update(sensor_pv, dt)
- # mv is already rounded in PIDController.update
- # System Update (Euler method)
- # dy/dt = (K*u - y) / Tau
- derivative_pv = (system_k * mv - current_pv) / tau
- current_pv += derivative_pv * dt
- # Store data
- self.time_data.append(t)
- self.target_data.append(target)
- self.input_data.append(mv)
- self.output_data.append(sensor_pv) # Plot noisy sensor data or clean system state? Usually PV implies what user sees.
- self.update_plot()
storedataでデータ格納してます。
入れているのは、時間と目標値、操作量、センサー値(ノイズあり)ですね。
センサー値を追加される処理でコメントがあります。
Plot noisy sensor data or clean system state? Usually PV implies what user sees.
簡潔にいうとグラフに出すのは、ノイズありのセンサー値?それともノイズなし?と聞いてます。
バイブコーディングをすると仕様があいまいなところはこのようなコメントが書かれていることがありますが、出力したときにAIからこのようなコメント書きました!みたいなこと言われないんですよね。。。
ですので、AIの成果物には一通り目を通すやAIにコメントをピックアップしてもらい断定できないものや、質問に近いコメントがないかを確認してもらうなどの工夫をする必要があります。
AIで生成すると、問題を見過ごしがちになるので、あえて作ったシミュレーションを否定的な意見を出してもらうことを前提にレビューをしてもらいました。
その結果、AIからは以下のコメントが返されました。
以下コメント文章です。
このロジックはシミュレーション実行の処理です。
初めにP、I、D、目標値、シミュレーション時間とノイズタイプを取得します。
そこからノイズを演算します。
ノイズ演算できたらPID制御を実行し入力値(mv:操作量)を決定します。
入力値からオイラー法を用いてノイズなしの出力値(*_pv:プロセス値)を決定しています。
AIが生成したコードをそのまま使用するのではなく、演算処理に潜在的な問題がないかレビューすることが重要です。 今回生成されたコードには、以下のようなレビューポイントがあります。
PID制御器の微分項は「誤差の変化率」を計算します。
- derivative = (error - self.prev_error) / dt
この実装では、ノイズを含んだセンサー値から誤差を計算しているため、ノイズが増幅されます。
`dt = 0.1` で割るということは、ノイズ成分が10倍に増幅されることを意味します。
影響:Kd(微分ゲイン)を大きくすると、グラフがガタガタになる現象が発生します。 これは実システムでも起こる現象であり、「微分項はノイズに敏感」という制御工学の重要な知見です。
積分項の実装を見ると、上限が設定されていません。
- self.integral = self.integral + (error * dt)
- 長時間の偏差がある場合、積分項が過大になる
- 目標値を大きく変更した場合、オーバーシュートが激しくなる
- Kiを大きくしすぎると制御が不安定になる
実用的なPID制御器では「アンチワインドアップ」という機構を実装して、積分項に上限・下限を設けます。
学習用シミュレータとしては、この問題が起きうる状態のままにしておくことで、積分ワインドアップの概念を体験できます。
シミュレーションループを見ると、`output_data` には `sensor_pv`(ノイズ込みの値)が格納されています。
- sensor_pv = current_pv + noise[i] # システム出力 + ノイズ
- self.output_data.append(sensor_pv)
- <注意点>
グラフの青線(Output)がガタガタしているのは、シミュレーションの問題ではなくセンサーノイズの表現です。
- 真のシステム出力を見たい場合は `current_pv` を使用する必要があります。
実システムでも、センサーから得られる値にはノイズが含まれるため、この挙動は現実的です。
システムの更新には前進オイラー法が使用されています。
- derivative_pv = (system_k * mv - current_pv) / tau
- current_pv += derivative_pv * dt
評価
- `dt/tau = 0.1/2.0 = 0.05` であり、安定性は十分
- 学習用途では精度は問題にならない
- より高精度が必要な場合は、ルンゲクッタ法などを検討
PIDの基本動作を理解する目的であれば、オイラー法で十分です。
エクスポートされるCSVのヘッダーは「目標値、入力値、出力値」となっています。
- writer.writerow(["目標値", "入力値", "出力値"])
制御工学の用語と対応させると、以下になります。
| CSVヘッダー | 制御工学用語 | 略称 | 意味 |
|---|---|---|---|
| 目標値 | Setpoint Value | SV | 制御の目標となる値 |
| 入力値 | Manipulated Variable | MV | PID制御器が出力する操作量 |
| 出力値 | Process Value | PV | センサーで測定した現在の値 |
「入力値」という名称は紛らわしいかもしれません。これは「制御対象への入力」であり、「PID制御器の出力」と同義です。 より明確にするなら「操作量(MV)」や「制御出力」とした方が分かりやすいでしょう。
やはり漏れがありましたね。
このような検証は実務をやる上で重要で、その他、セッションを変えてみるなどした方が良いかもしれません。
実装確認できました。大体問題ないかなと思いますがノイズ値の演算や細かなところは少し違うかなと思うところが出てきました。
今回のGemini 3 Proは汎用的なモデルなのでソフトウェア開発現場でよく使われているClaudeなど別のLLMを使用するとUIやロジックの流れが異なると思います。
それもまたバイブコーディングの面白さの一つなのかもしれません。
小さな機能の実装であっても、これだけの評価・検証が必要である点に留意が必要です。
どんなに性能の良いAIでも明確にバグだと扱ってはくれません、「修正必要ありませんか?」などの修正の提案にとどまるのでそれを見逃さないようにしないといけません。
設計知識を持っておくと関数分割をもう少し考えたり(例えば、PIDの偏差、微分、積分を分割してフィルタを追加しやすくするなど)ドメイン知識を持ってレビューすることで潜在的な問題点や改善点を発見できます。
AIにコーディングしてもらうときはソース管理が重要になります。今回は発生しませんでしたが、急にソースコードを破壊し始めるのでGitで小さくコミットすることをおすすめします。
特にAIがPowerShellを使いだしたら文字エンコーディングがおかしくなり・・・・となり最終的に重要なファイルを削除し始めます。。。
GitHub Copilotを使ってバイブコーディングをしていきました。
最近は、GitHubCopilotよりもClaudeCodeのほうがホットな話題になってますよね。
今回使用してませんがAnthropic社のClaude系等のコーディング能力はすさまじいものがあります。いろいろなMCPを簡単に設定できるのがよいそうですよね。精度もよいですしね。
最近Anthropic社のハッカソンがあったようで優秀な成績をマークした方がAIコーディングで使用している設定関連をGitHubに公開していました。少し見てみてもよいかもしれません。この記事以上にいろいろとドキュメント化されているのでこれを見てみるのもよいかもしれません。
>>バイブコーディング
>>バイブコーディングとは?~人xAIで加速する新しい開発スタイル
>>PID制御 MathWorks
LineではQRコードから登録していただくか「友だち追加」ボタンから登録できます。メールで登録ご希望の方はこちらから
※登録頂いた個人情報は次の目的で利用します。 ①テクノヒントからの情報発信②テクノヒント運用に関するアンケート依頼の案内など
